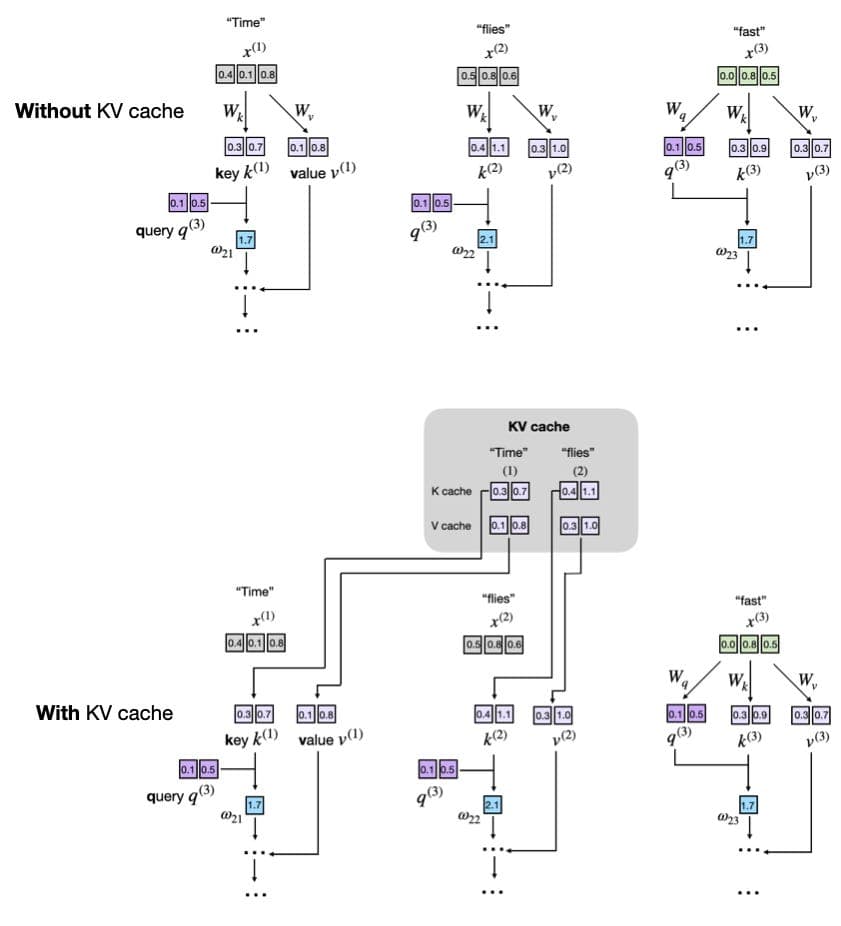
KV caches are the primary technique making LLM inference fast enough for production. The mechanism is simple: instead of recomputing key and value matrices for every token in the sequence at each generation step, the model stores those intermediate attention computations and retrieves them. Without a KV cache, generating a 100-token response means the model reprocesses token 1 roughly 100 times. With one, it processes each token's K and V vectors exactly once.
The cost is real. KV caches increase memory consumption proportionally to sequence length and number of layers, which is why Sebastian Raschka excluded them from his book 'Building a Large Language Model From Scratch'. They also cannot be used during training, only inference. The article delivers a from-scratch Python implementation, meaning you can trace every matrix operation and see exactly where the cache is populated, read, and extended across generation steps. That implementation is the reason to read the full piece, not just the summary.
This tutorial sits at the intersection of theory and working code, covering the attention mechanism internals that make caching possible and the specific redundancy in autoregressive generation that makes it necessary. If you work with LLMs in production and have treated KV caching as a black box, this closes that gap.
[READ ORIGINAL →]