Qwen3's 235B-Instruct variant sits at rank 8 on the LMArena leaderboard, tied with proprietary Claude Opus 4. The only open-weight models above it are DeepSeek 3.1, which is 3x larger, and Kimi K2, which is 4x larger. It runs under Apache License v2.0 with no additional usage restrictions, and spans model sizes from 0.6B dense to 480B Mixture-of-Experts. On September 5th, Alibaba quietly released a closed-source 1T parameter variant that outperforms all of the above on major benchmarks.
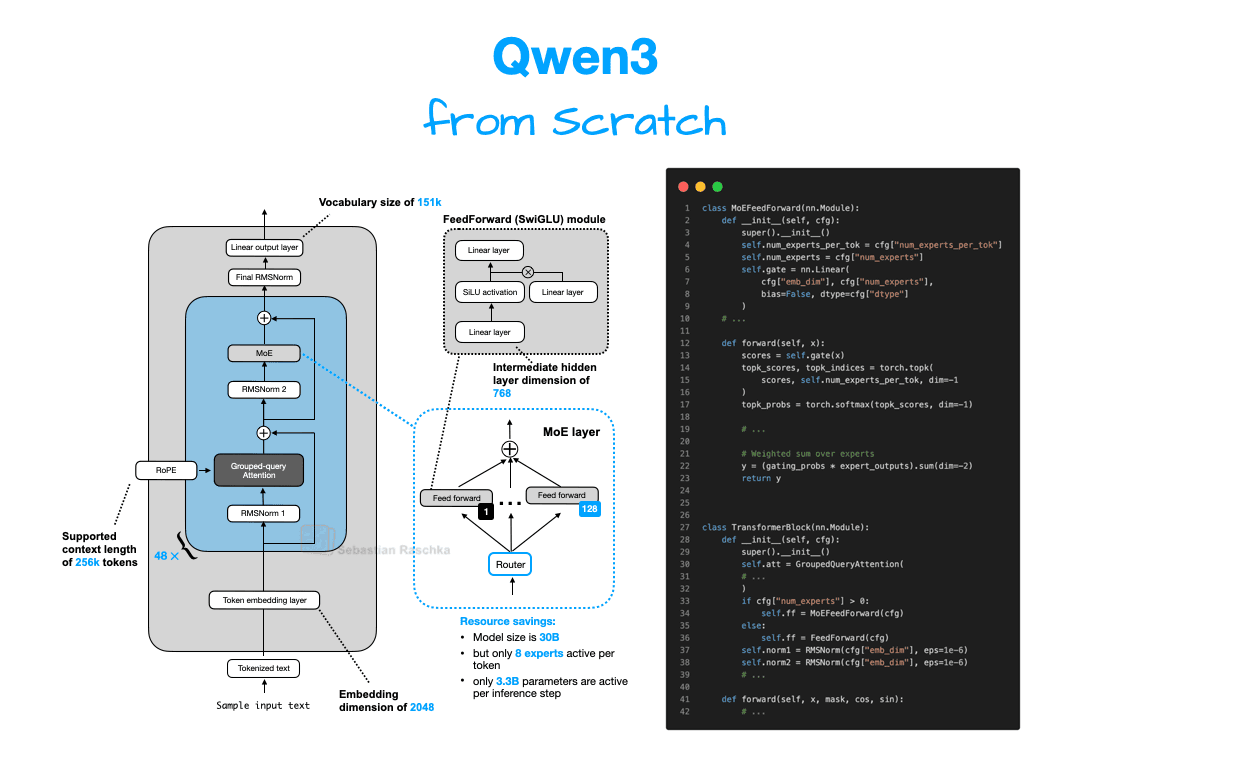
Sebastian Raschka builds Qwen3 from scratch in pure PyTorch, covering both the dense and MoE architectures. This is the third installment in a series: the first compared major 2025 open-weight architectures broadly, the second analyzed components conceptually from GPT-2 forward. This piece is where the abstractions stop and the code starts. The verbosity is the point: each block is a transferable building block for your own experiments.
Read the full article if you want working PyTorch implementations you can actually run and modify, not just architecture diagrams. The MoE implementation alone is worth the time. The original appeared in Raschka's Ahead of AI newsletter and is best read in a browser, not email, due to code formatting.
[READ ORIGINAL →]