Scaling model size hit a wall. GPT-4.5 and Llama 4 landed to muted reactions because both are conventional models trained without explicit reinforcement learning for reasoning. The market noticed. Meanwhile, xAI Grok and Anthropic Claude have already shipped toggleable 'extended thinking' modes, and OpenAI's o3 used 10 times more training compute than o1, with all of that extra compute directed at RL-based reasoning post-training.
The signal here is structural, not cyclical. Raw parameter count and data volume are no longer the primary levers for capability gains. Reinforcement learning applied specifically to reasoning tasks is now the credible path forward, and it is already separating the leaders from the laggards in measurable benchmark performance on hard problem-solving tasks.
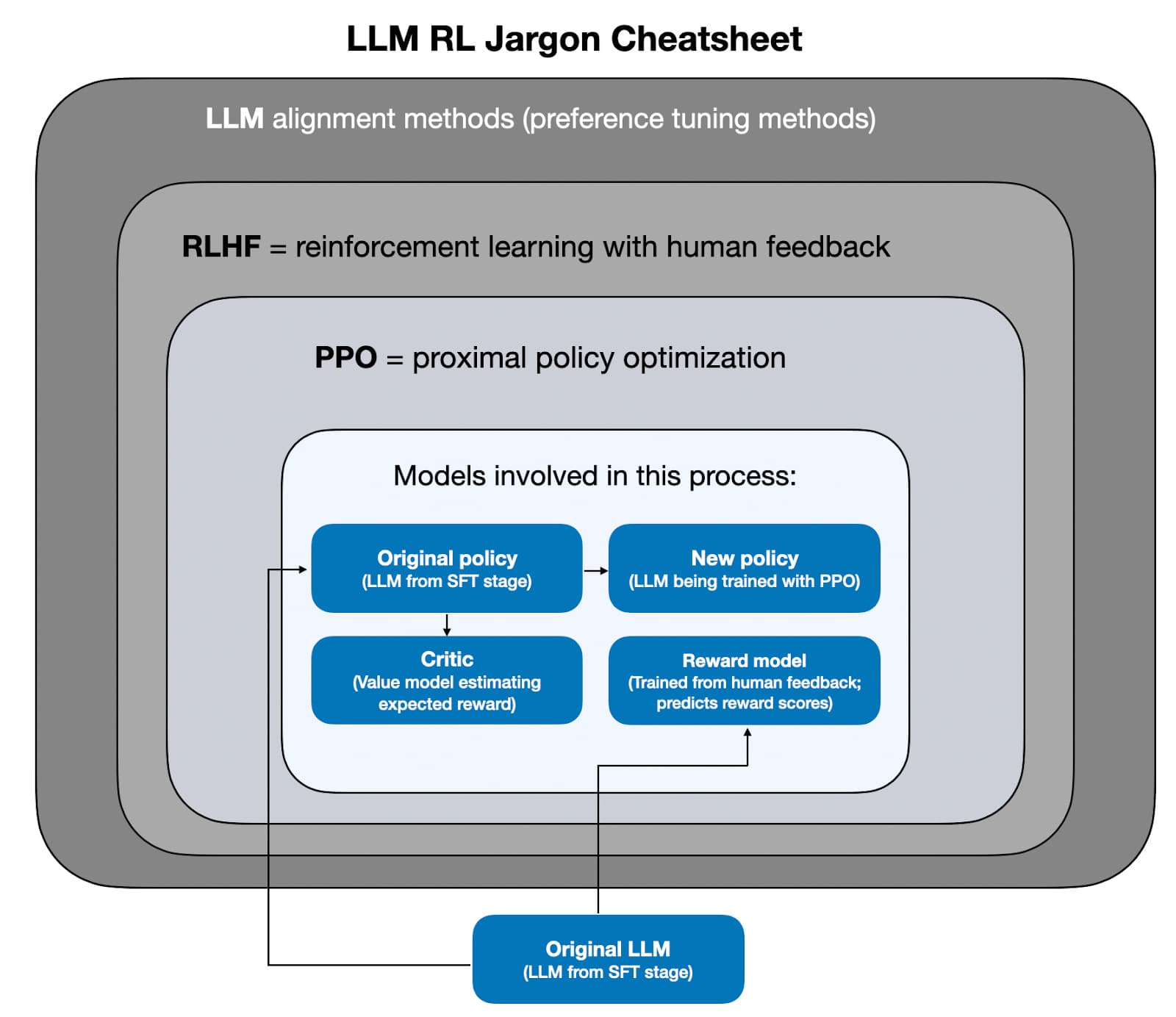
The original piece from Ahead of AI maps the current RL-for-reasoning landscape in full, including the specific methods, the tradeoffs, and what the pipeline looks like when reasoning post-training becomes standard. The conclusion is worth knowing. The reasoning behind it is worth reading.
[READ ORIGINAL →]