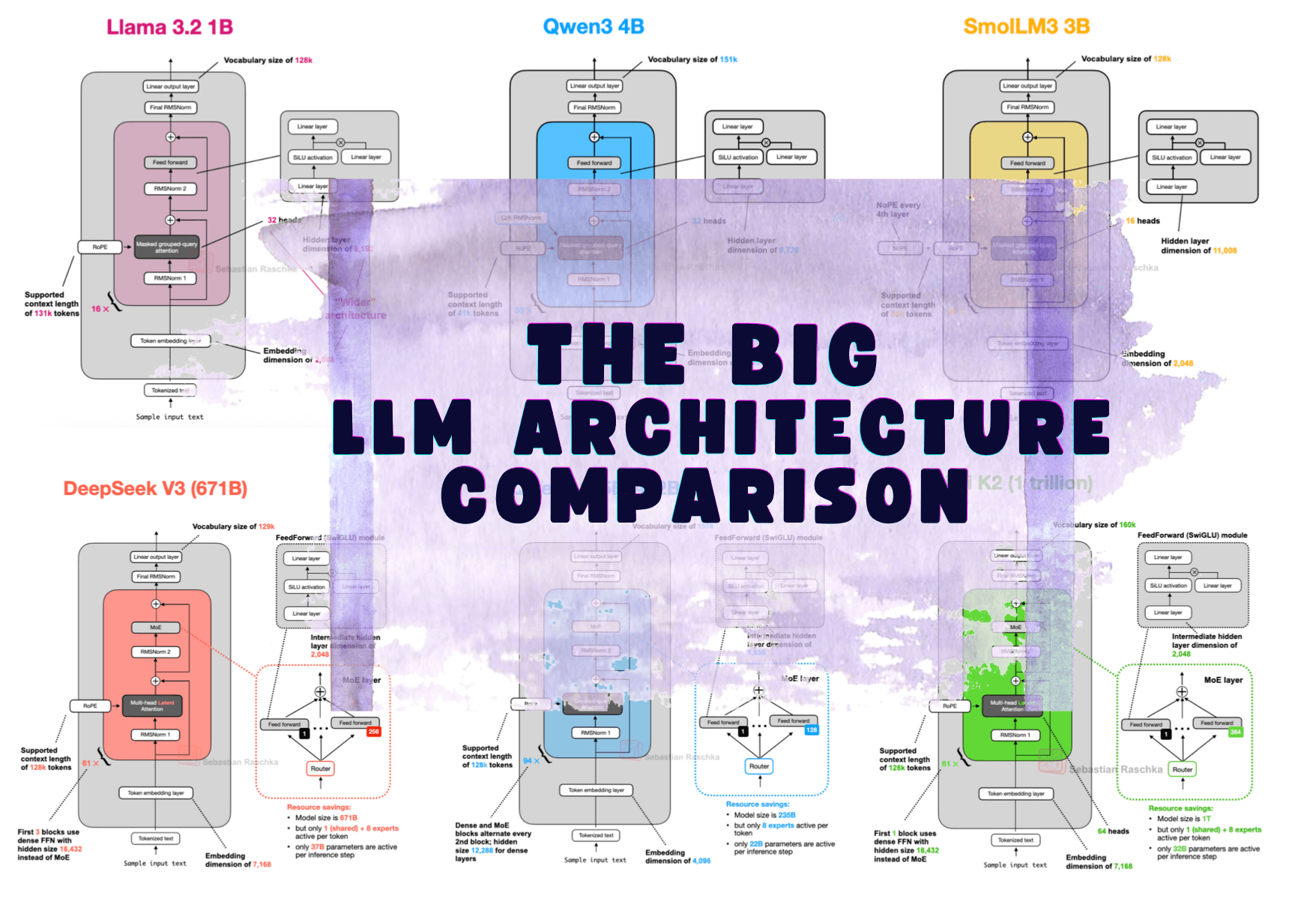
Seven years after the original GPT architecture, models like DeepSeek V3 and Llama 4 are still recognizable descendants of the same transformer blueprint. The headline changes are real but incremental: absolute positional embeddings replaced by RoPE, Multi-Head Attention largely swapped for Grouped-Query Attention, GELU activation replaced by SwiGLU. This piece, updated April 2, 2026 to include Gemma 4, does not chase benchmarks or training recipes. It maps the structural decisions that define today's flagship open models across more than 23 architectures.
The comparison problem is real. Datasets, hyperparameters, and training techniques differ wildly between labs and are rarely documented with enough precision to draw clean conclusions. The author, Sebastian Raschka, sidesteps that trap entirely by focusing only on what can be directly observed: the architecture. That constraint is the article's strength. You learn what choices developers are actually making at the layer level, not what their marketing says about performance.
DeepSeek V3 and R1 anchor the analysis, with R1's January 2025 release pulling V3's December 2024 architecture into the spotlight. The full piece works through more than 23 models including Llama 4 and Gemma 4, making it one of the more complete structural surveys published this cycle. If you work with or evaluate open models, the architecture comparison table alone is worth the read.
[READ ORIGINAL →]