OpenAI released two open-weight models this week, gpt-oss-120b and gpt-oss-20b, their first public weight release since GPT-2 in 2019. Both models can run locally using MXFP4 quantization, a precision format that compresses weights enough to fit on a single consumer GPU without destroying benchmark performance.
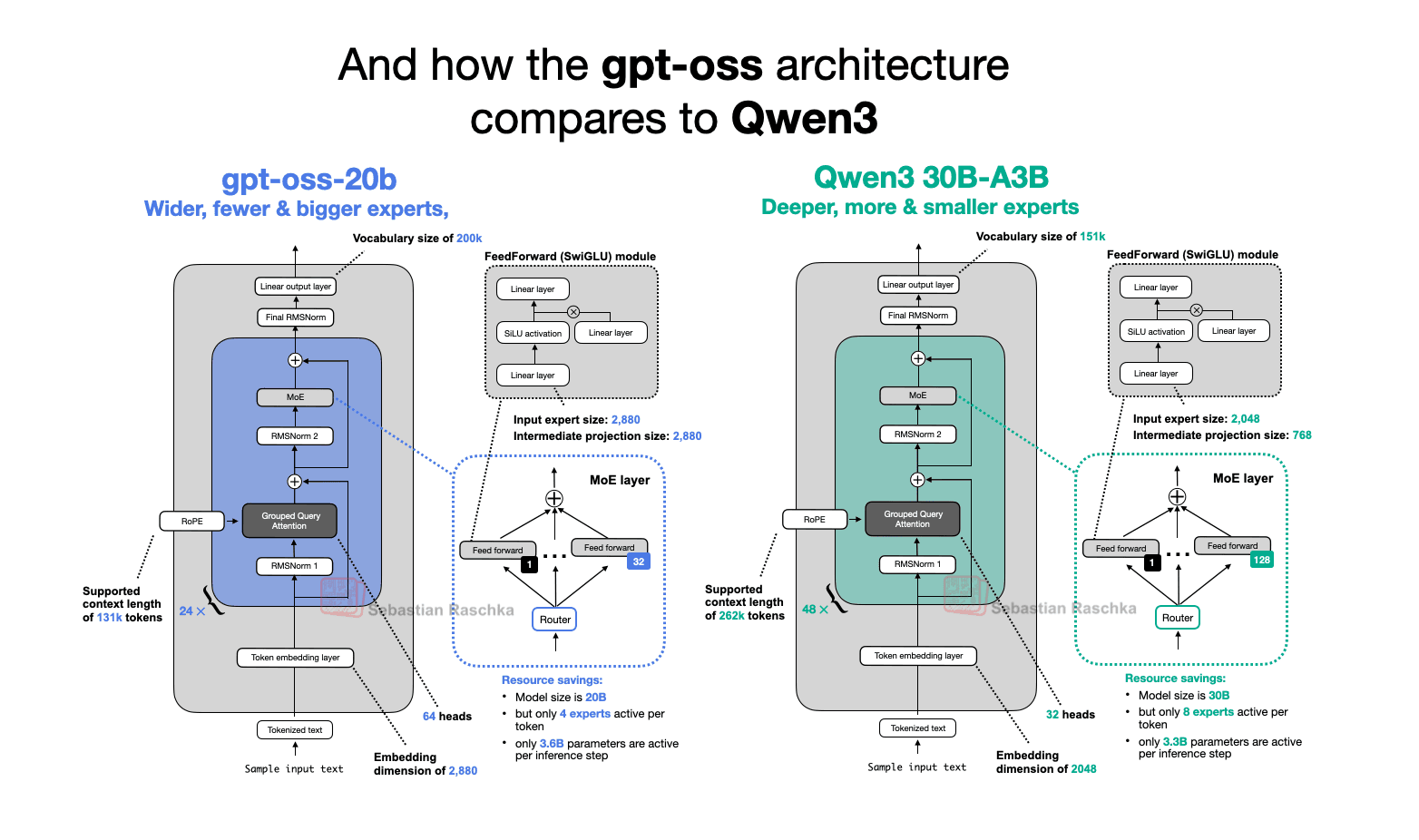
The author spent several days reading the source code and technical reports, and the architecture is not a radical departure from current transformer norms. What it is, specifically, is a set of deliberate tradeoffs: width versus depth choices benchmarked directly against Qwen3, attention bias and sink behavior that affects long-context stability, and a parameter scaling strategy that separates these two models from how GPT-2 approached the same problem six years ago.
The full piece runs through side-by-side architecture comparisons, the mechanics of MXFP4, and benchmark numbers placed against GPT-5, which OpenAI announced days after the open-weight drop. The benchmark section alone makes the original worth reading, because it frames what OpenAI is actually willing to give away and what that implies about where GPT-5 sits above it.
[READ ORIGINAL →]