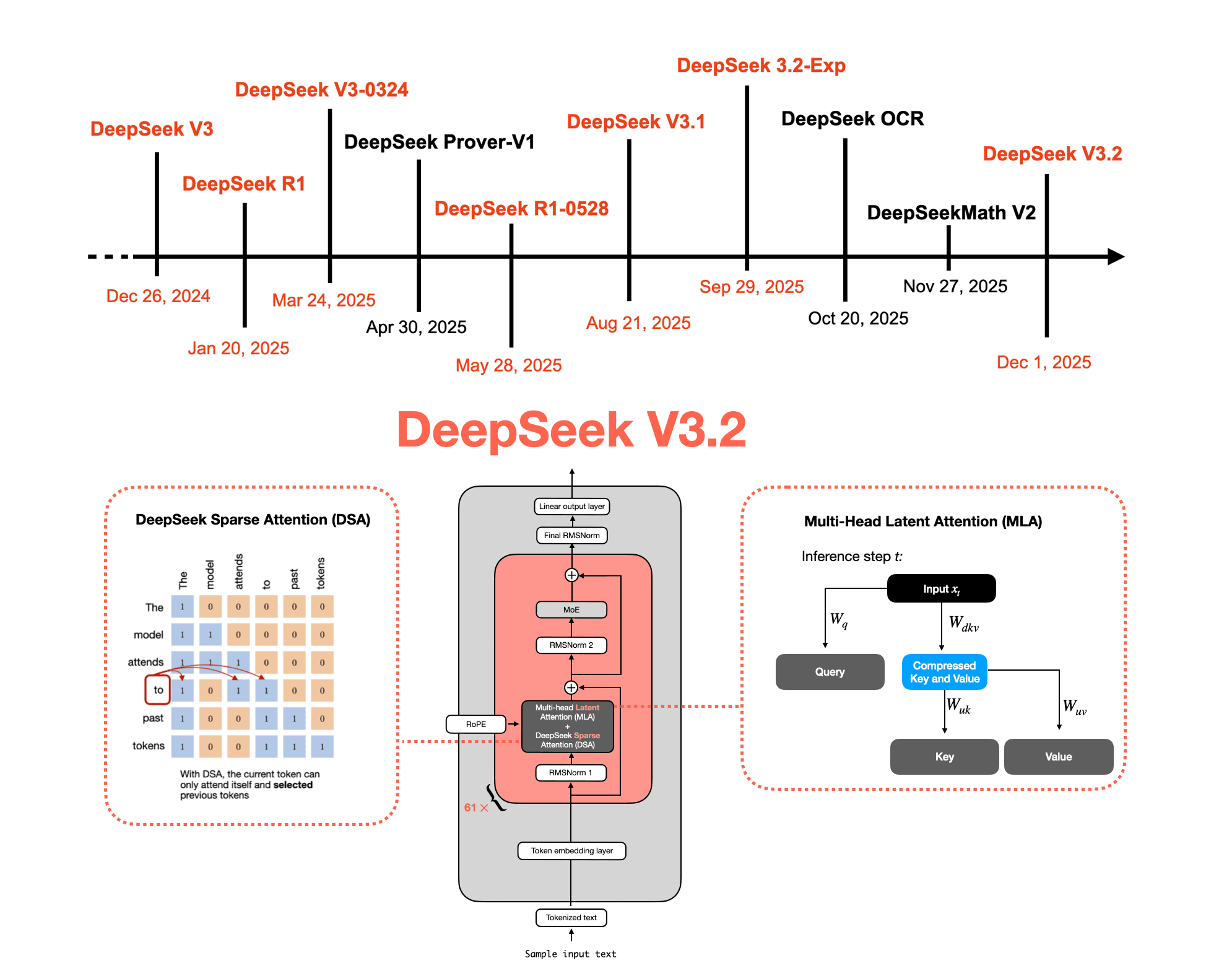
DeepSeek V3.2, released January 1, 2026, benchmarks at GPT-5 and Gemini 3.0 Pro performance levels and is available as an open-weight model. The team dropped it over a US holiday weekend, the same playbook used for DeepSeek V3 in December 2024. That original V3 release went largely unnoticed until DeepSeek R1, built on the identical architecture, turned the company into a credible open-weight alternative to OpenAI, Google, xAI, and Anthropic.
This article started as a section addition to Sebastian Raschka's existing Big LLM Architecture Comparison piece, then grew into a standalone deep dive because the technical report contains too much material to compress. The coverage spans the full DeepSeek release timeline, architectural changes, sparse attention mechanisms, and reinforcement learning updates between V3 and V3.2. Those implementation details are where the real value is, not just the benchmark numbers.
If you already track open-weight model development, the architecture delta between V3 and V3.2 is the section to read. Raschka maps the specific changes with enough technical precision to understand what DeepSeek actually modified versus what stayed fixed from R1. The question this piece sets up but does not fully close: how long before a V3.2-based reasoning model follows the same path R1 did.
[READ ORIGINAL →]